Son of Sara : Developing a new LLM-based
Embodied Conversational Agent.
Overview
As part of our ongoing work on socially capable conversational agents, the team launched what we are calling Son of SARA (see the SARA project on this page), an embodied conversational agent designed to support natural and effective interaction with human users, relying on both rapport and task effectiveness to assure good collaboration between human and agent. In this context, and as always, the project aims to equip dialogue agents with both verbal and non-verbal interactional skills that are essential for collaborative communication. Building on our lab’s tradition to build socially aware ECAs, we aim to elevate their naturalness and adaptability, alongside other key attributes, using the robust generalization capabilities of LLMs and cutting-edge deep learning models.
Our current system follows the team’s traditional approach, utilizing a modular/cascaded pipeline with specialized modules for each conversational phenomenon. The processing and generative pipeline will allow the system, from the voice of the user, to generate a suitable agent response. Each module of the pipeline can process or generate a different combination of multimodalities (speech, gesture, head and face movements, (text, audio). To ensure that the complexity of the modular architecture and its deep learning models won’t prevent the agent from interacting with the user in real time, we decided to go with an incremental system, following the approach of several dialogue systems and conversational agent from colleagues, such as (Schlangen & Skantze, 2011).
First version : Focusing on speech
We initially focused on building a conversational agent, without the embodied part of the agent. We successively created an agent that people can interact with, in real time, with a fairly flexible approach towards the scenario of interaction (free discussion, Q&A, collaborative task, etc). That first version of the agent, that we might call the “skeleton” of the pipeline, contains all required models to allow a speech conversation with : It captures and transcribes the user’s voice with the Microphone and Automatic speech recognition (ASR), generates a suitable text then spoken response with the LLM and Text to speech (TTS). The dialogue dynamics are handled with the Voice Activity Detection (VAD) and Dialogue Manager modules. To qualitatively test that first version of the agent, we mimicked the collaborative task used in our Collab team’s longitudinal study which consist in discussing an image and coming up with hypothesis regarding the different image’s elements (you’ll soon be able to find more information in the corresponding Collab study page).
Non Verbal Behavior
Continuing the first agent version, we focused on extending it beyond spoken interaction by adding a visual and embodied dimension to the conversation. Building on an existing conversational framework enabling spoken dialogue, the team developed the agent’s virtual body and implemented the software infrastructure required to synchronize non-verbal behaviors with speech. This included the design and implementation of preliminary rule-based models for the generation of facial expressions and gestures, allowing the agent to produce visible communicative signals aligned with its speech turns.


Figure 1 : Son of Sara’s 20 years old virtual body during a conversation
The gesture generation system aims to produce plausible, semantically relevant co-speech gestures in real-time during agent-user interaction. Initially, the team explored a retrieval-based approach, selecting gestures from a pre-existing gesture library based on verbal and syntactic cues extracted from the agent’s speech. This system used transformer-based encoders (BGE/MiniLM) to embed utterances, then ranked candidate gestures via consensus re-ranking across multiple semantic views. While functional and fast, this method lacks flexibility, often producing generic scripted gestures that are vaguely appropriate rather than movements finely tailored to context.
Current development focuses on transitioning toward a generative model capable of producing diverse gesture types: deictic (pointing), iconic (depicting concrete concepts), and metaphoric (representing abstract ideas), rather than relying predominantly on beat gestures (rhythmic movements aligned with speech prosody) which is what most SOTA models suffer from at the moment. This shift prioritizes both synchronization and semantic appropriateness of non-verbal behaviors.
The generative approach contends with two data sources. Motion capture (e.g., BEAT/BEAT2 datasets in SMPL-X format (Liu et al., 2024)) provides high-fidelity ground truth but is actor-biased and limited in variety. Reconstructed 3D motion from monocular video via pose estimators (HMR, Hamer, haptic) (Agrawal et al., s. d., Pavlakos et al., 2023, Shen et al., 2024) is cheaper and more scalable but introduces noise : temporal jitter, depth ambiguity, and occlusion artifacts which requires post-processing to recover usable motion.
With data in hand, the goal is to evaluate leading 3D motion generation frameworks: diffusion models (DiffSHEG (Chen et al., 2024), STARGATE (Abel et al., 2024)), token-based autoregressive models (VQ-VAE discretization followed by GPT-style generation (Zhang et al., 2024)), and many more. This exploration lays groundwork for future extensions to co-listening behaviors.
Turn Taking
In parallel, the project advanced the agent’s conversational dynamics by improving its turn-taking capabilities. A predictive model based on voice activity was integrated to enable the agent to anticipate turn transitions during interaction. This contributes to more interactive and rhythmically natural exchanges, bringing agent–human conversations closer to the temporal structure of human–human dialogue.
In human conversation, listeners naturally anticipate upcoming turn transitions while simultaneously planning their responses. This dual cognitive process, monitoring for turn-yielding cues while preparing a follow-up (see Fig 2), constitutes the fluidity of human-human interaction. To replicate this dynamic, we implemented a system combining turn-shift prediction with early answer generation.
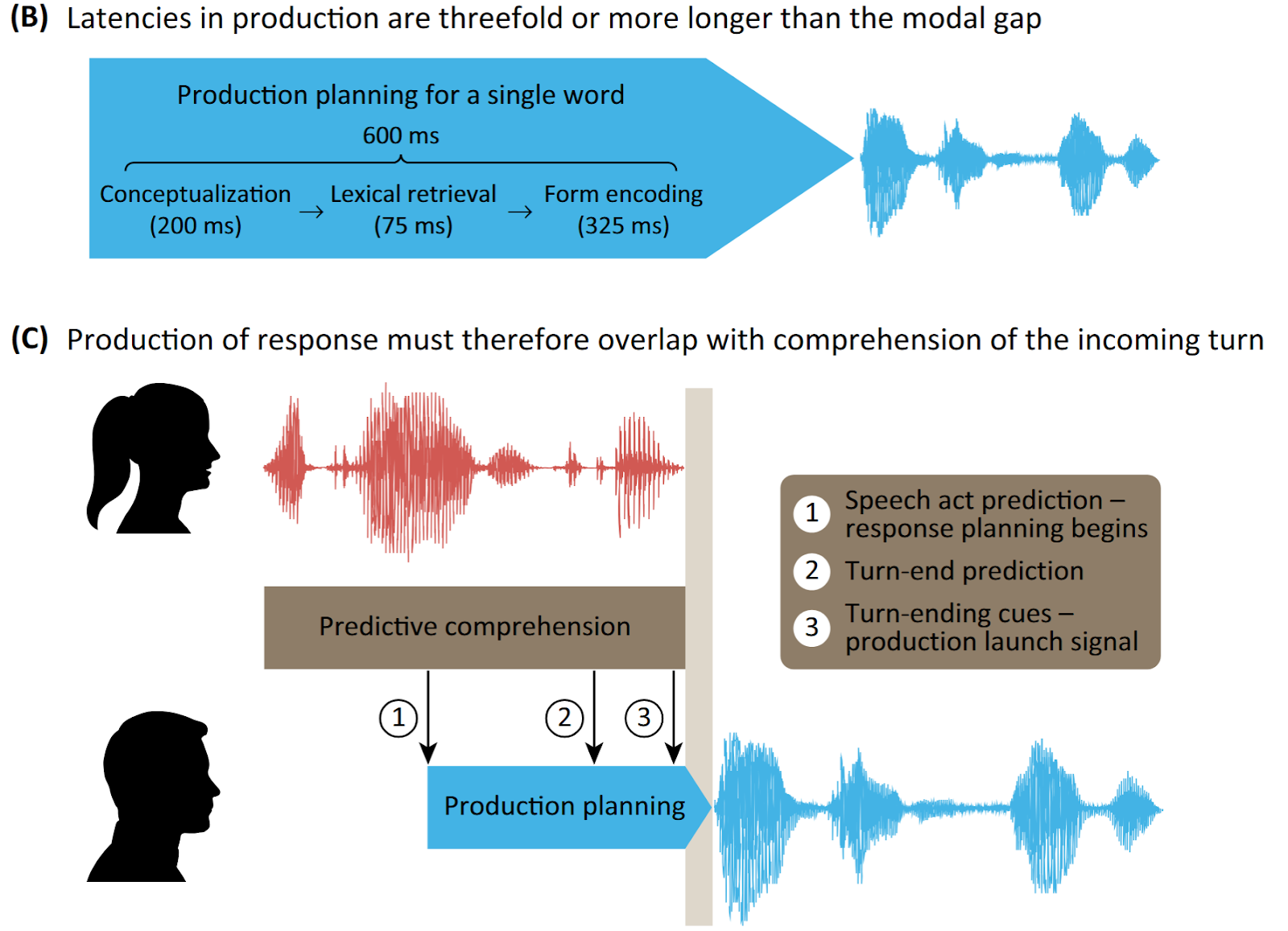
Figure 2 : Projection of interlocutor’s turn to predict end of turn (Levinson, 2016)
Our approach builds primarily on the work of (Ekstedt & Skantze, 2022) and their Voice Activity Projection (VAP) model for predictive turn-taking. VAP monitors ongoing conversations in real-time and predicts future voice activity patterns for both speakers within a 2-second window (see Fig. 3). By applying threshold-based decision rules to these predictions, we developed a set of behaviours that enable the agent to determine appropriate moments to initiate speech. This combination of predictive modeling and generation rules significantly reduced response latency and enhanced the conversational rhythm.
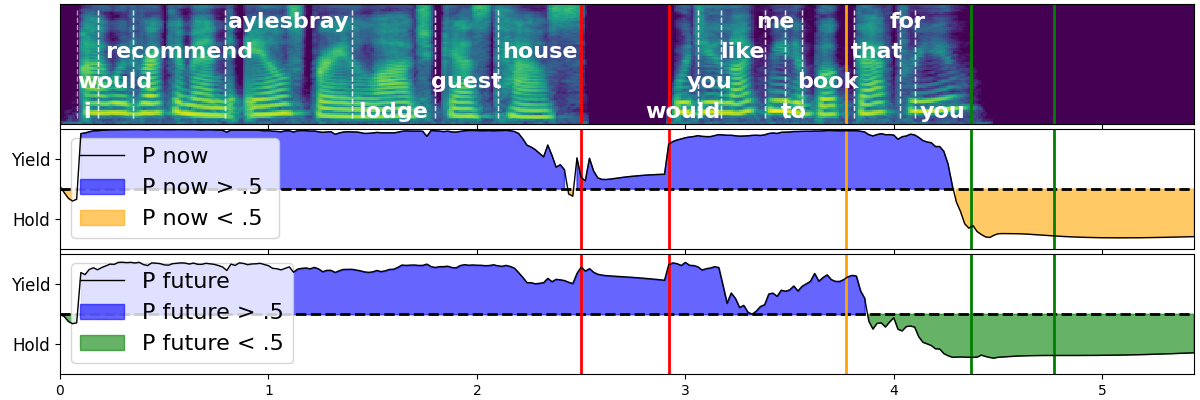
Figure 3 : VAP turn taking prediction model real time execution (Ekstedt & Skantze, 2022)
Another addition to our pipeline involves initiating response generation before the user’s turn concludes (Skantze & Irfan, 2025). When VAP predicts an imminent turn yield, the system begins generating a response while continuing to process incoming speech (see Fig 4). If the user introduces information that substantially alters the meaning of their turn, the initial generation is aborted and restarted using the complete transcription from the automatic speech recognition (ASR) system.

Figure 4 : Example of a VAP-monitored SDS real time execution (Skantze & Irfan, 2025)
While developing the turn-taking module, our team collaborated with Prof. Koji Inoue from Kyoto University, whose research focuses on enhancing naturalness in conversational AI (Inoue et al., 2024a, Inoue et al., 2024b). Along with his team, we are developing one of the first predictive turn-taking model for French dyadic interactions.
Current Architecture
Together, these developments mark a significant step toward the fully embodied nature of the Son of SARA conversational agent. They provide a solid foundation for future work on data-driven, real-time gesture generation conditioned on vocal features, as well as on further refinements of turn-taking models, including adaptation to additional languages. The current version of the dialogue system can be pictured as in the following graphic :
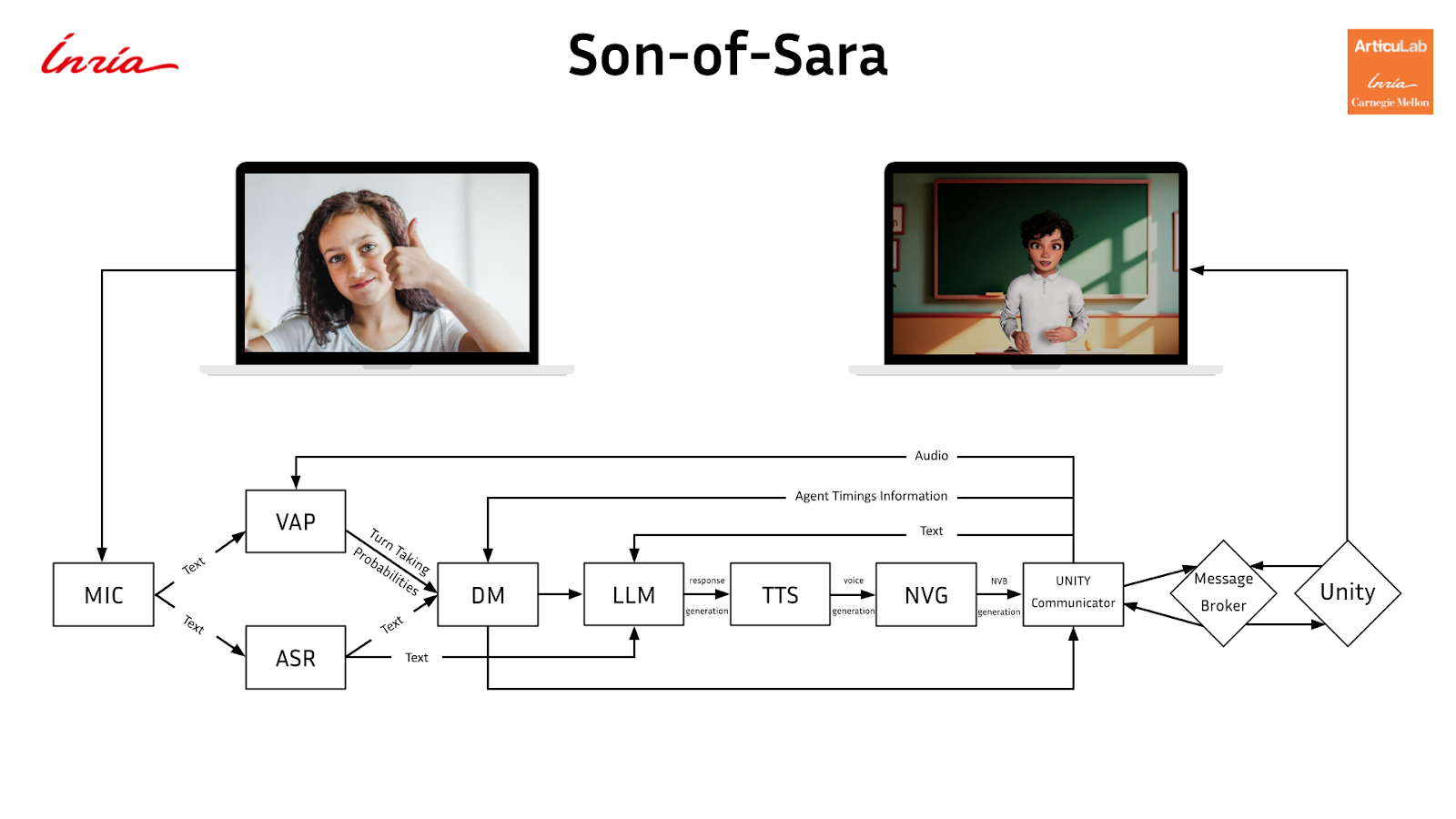
Figure 5 : Son of Sara’s current dialogue system’s modular architecture
References
Abel, L., Colotte, V., & Ouni, S. (2024). Towards interpretable co-speech gestures synthesis using STARGATE. Companion Proceedings of the 26th International Conference on Multimodal Interaction, 138‑146. https://doi.org/10.1145/3686215.3688819
Agrawal, V., Akinyemi, A., Alvero, K., Behrooz, M., Buffalini, J., Carlucci, F. M., Chen, J., Chen, Z., Cheng, S., Chowdary, P., Chuang, J., D’Avirro, A., Daly, J., Dong, N., Duppenthaler, M., Gao, C., Girard, J., Gleize, M., Gomez, S., … Zollhoefer, M. (s. d.). Seamless Interaction : Dyadic Audiovisual Motion Modeling and Large-Scale Dataset.
Chen, J., Liu, Y., Wang, J., Zeng, A., Li, Y., & Chen, Q. (2024). DiffSHEG : A Diffusion-Based Approach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation (arXiv:2401.04747). arXiv. https://doi.org/10.48550/arXiv.2401.04747
Ekstedt, E., & Skantze, G. (2022). Voice Activity Projection : Self-supervised Learning of Turn-taking Events. Interspeech 2022, 5190‑5194. https://doi.org/10.21437/Interspeech.2022-10955
Inoue, K., Jiang, B., Ekstedt, E., Kawahara, T., & Skantze, G. (2024a). Multilingual Turn-taking Prediction Using Voice Activity Projection. In N. Calzolari, M.-Y. Kan, V. Hoste, A. Lenci, S. Sakti, & N. Xue (Éds.), Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (p. 11873‑11883). ELRA and ICCL. https://aclanthology.org/2024.lrec-main.1036/
Inoue, K., Jiang, B., Ekstedt, E., Kawahara, T., & Skantze, G. (2024b). Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection. arXiv. https://doi.org/10.48550/ARXIV.2401.04868
Levinson, S. C. (2016). Turn-taking in Human Communication – Origins and Implications for Language Processing. Trends in Cognitive Sciences, 20(1), 6‑14. https://doi.org/10.1016/j.tics.2015.10.010
Liu, H., Zhu, Z., Becherini, G., Peng, Y., Su, M., Zhou, Y., Zhe, X., Iwamoto, N., Zheng, B., & Black, M. J. (2024). EMAGE : Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling (arXiv:2401.00374). arXiv. https://doi.org/10.48550/arXiv.2401.00374
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., & Malik, J. (2023). Reconstructing Hands in 3D with Transformers (arXiv:2312.05251). arXiv. https://doi.org/10.48550/arXiv.2312.05251
Schlangen, D., & Skantze, G. (2011). A general, abstract model of incremental dialogue processing. Dialogue & Discourse, 2(1), 83‑111.
Shen, Z., Pi, H., Xia, Y., Cen, Z., Peng, S., Hu, Z., Bao, H., Hu, R., & Zhou, X. (2024). World-Grounded Human Motion Recovery via Gravity-View Coordinates. SIGGRAPH Asia 2024 Conference Papers, 1‑11. https://doi.org/10.1145/3680528.3687565
Skantze, G., & Irfan, B. (2025). Applying General Turn-Taking Models to Conversational Human-Robot Interaction. 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 859‑868. https://doi.org/10.1109/HRI61500.2025.10973958
Zhang, Z., Ao, T., Zhang, Y., Gao, Q., Lin, C., Chen, B., & Liu, L. (2024). Semantic Gesticulator : Semantics-Aware Co-Speech Gesture Synthesis. ACM Trans. Graph., 43(4), 136:1-136:17. https://doi.org/10.1145/3658134